Abstract
Speech-driven 3D facial animation has attracted significant attention due to its wide range of applications in animation production and virtual reality. Recent research has explored speech-emotion disentanglement to enhance facial expressions rather than manually assigning emotions. However, this approach face issues such as feature confusion, emotions weakening and mean-face.
To address these issues, we present EcoFace, a framework that (1) proposes a novel collaboration objective to provide a explicit signal for emotion representation learning from the speaker's expressive movements and produced sounds, constructing an audio-visual joint and coordinated emotion space that is independent of speech content. (2) constructs a universal facial motion distribution space determined by speech features and implement speaker-specific generation. Extensive experiments show that our method achieves more generalized and emotionally realistic talking face generation compared to previous methods.
Proposed Method
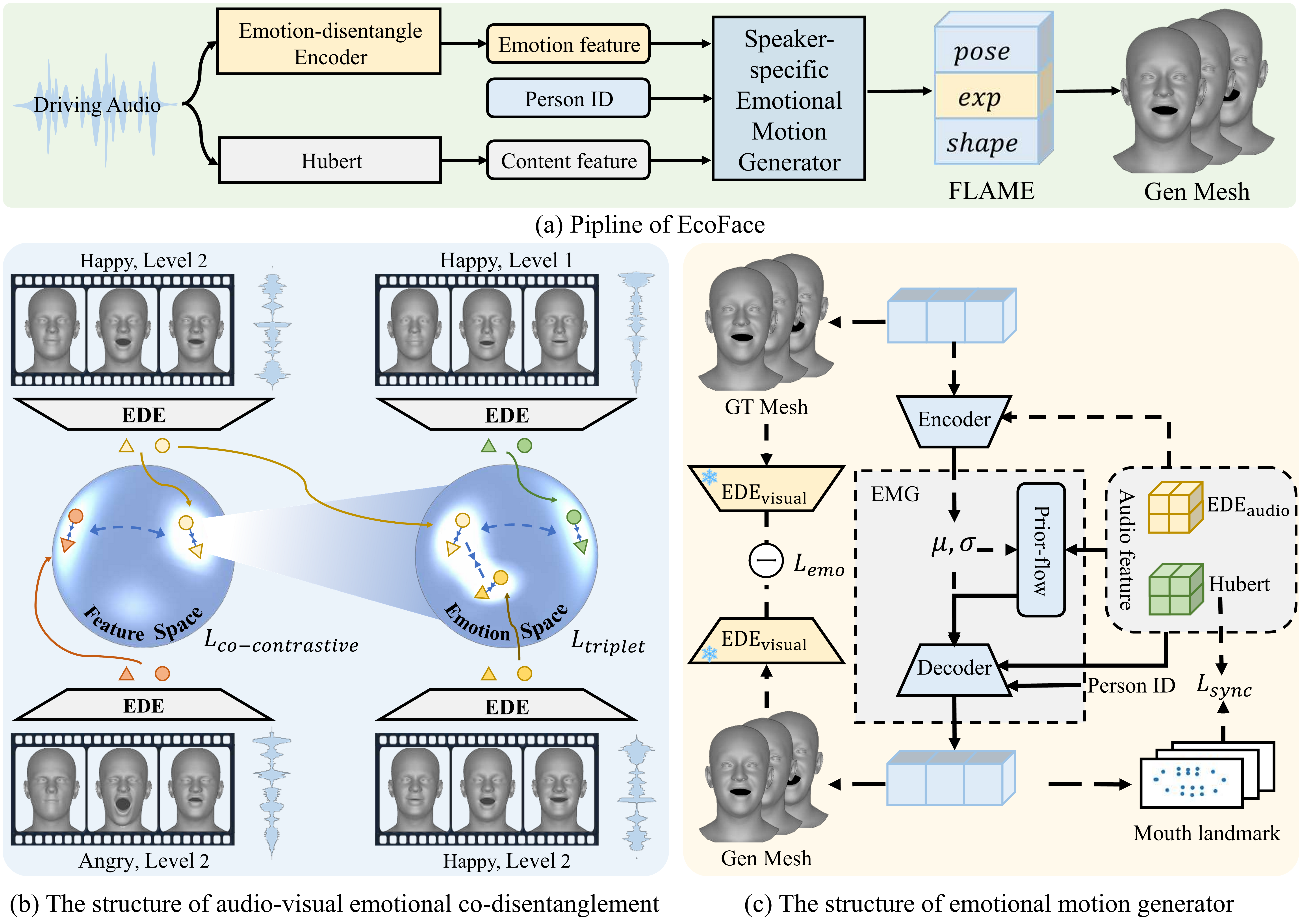
Overview of the proposed EcoFace. Subfigure (a) depicts the disentanglement of emotional and content features from
audio, generating speaker-specific FLAME and rendering expressive meshes. Subfigure (b) illustrates how features
corresponding to different emotions move away from each other in the feature space (left), while features
representing different emotion intensities remain distinct within the same emotional space, and speech-video pair
features are encouraged to be as similar as possible. Subfigure (c) shows the structure of the emotional motion
generator. Dashed arrows indicate processes performed only during training, and only the dashed rectangle part is
used during inference.